What I Learned from 2.75 Million Bike Rides
What do you think is the most popular bicycle spot is in San Francisco? I’ll give you a hint, over 129,000 people recorded being there in the last year. It is also near a train station.

Most Popular Spot to Bike
The corner of Townsend & 4th St had 129,832 people start/end their bike trip at this exact spot. Surprisingly this one corner it beat out the entire Ferry terminal by over 200% and nothing else even came close. To generate these exact numbers we had to crunch ALOT of data and dig deep into Ford’s GoBike Program.
The Data Source
For those unfamiliar with Ford GoBikes, it is a program that allows users to rent bicycles for a short period of time. This particular program relies on docks that a bike is both rented from and returned to. Ford publishes this program’s data publicly as both a monthly CSV and as a real-time data stream. This data provides phenomenal insight into the travel habits of people and allows us to see the city of San Francisco through the lens of self-powered commuters.
The Challenge
The main challenge we faced when processing this data was reliably cleaning in a quick and efficient manner. Many of the rows had a NULL value for Lat/Lon that we wanted to remove before sending the data to our analytics database. The NiFi validate schema processor allows us to do this quickly and efficiently without resorting to messy regex commands.
In short NiFi can validate any incoming files(CSV, JSON, AVRO, etc) and check them against an internal ‘schema registry’. This is particularly useful because the same schema can be re-used between files or even between formats. I will be publishing a deep dive into the schema registry soon on our Calculated Systems company page so follow us there if you would like more information on that
The NiFi Flow
This section assumes a base level understanding of Apache NiFi. NiFi for Dummies is a great free ebook I authored that walks you through the core concepts!
https://www.calculatedsystems.com/nifi-for-dummies
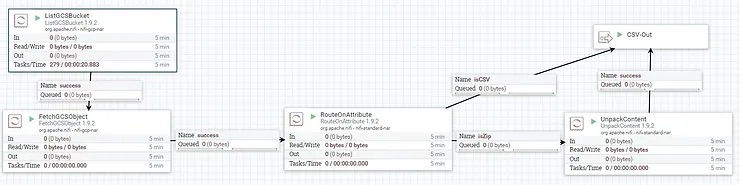
The complete flow involves 3 processor groups, Loading the Data, Validating, and Putting to BigQuery. The loading the data processor group lists all the files in the Google Cloud Storage Bucket, retrieves them, and unzips any compressed files. The credentials for this step are covered in more depth by our controller service guide found here
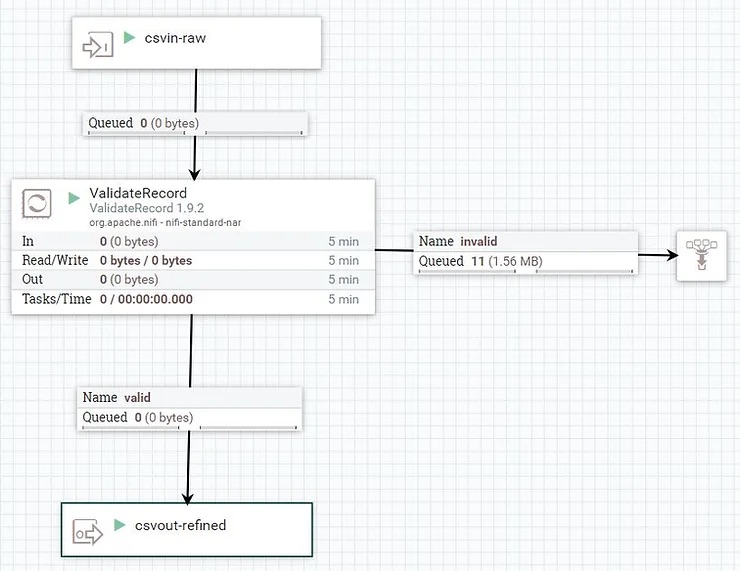
The validating steps is the most interesting as it enables us to eject individual malformed rows without failing the whole file. As you can see from the configuration below we simply read-in and write-out a CSV while referencing a specific schema in the registry. We experimented with breaking the files into smaller chunks of 10,000 rows but did not notice a significant thruput increase. If the files were larger, splitting them or assigning more concurrent tasks to the processor potentially could have further boosted performance but was not necessary in this case.
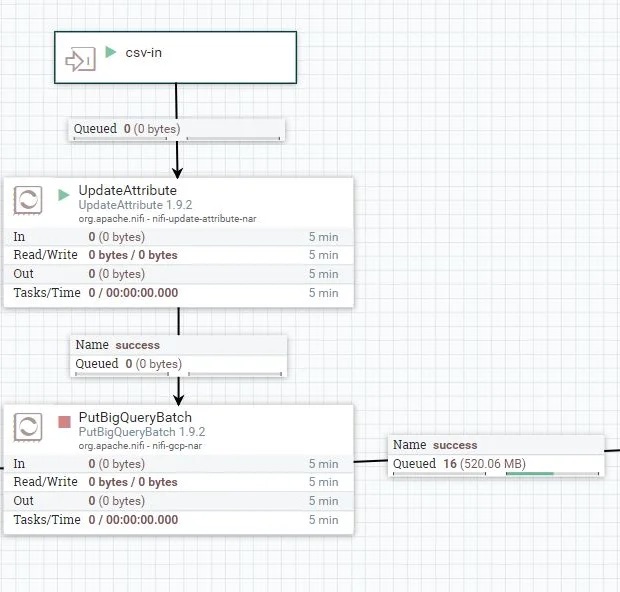
For writing the data out we simply took the files and sent them to the Bigquery batch processor. BigQuery is a useful serverless database that excels at crunching large amounts of data allowing us to process the nearly 3million rows in ~0.9 seconds.
Examples and Next Steps
Reach out to us at info@calculatedsystems.com if you are interested in a live demo or would like more information!
Download the case study as a PDF here – Complete with Ford GoBike Schemas