A story in 3 Parts
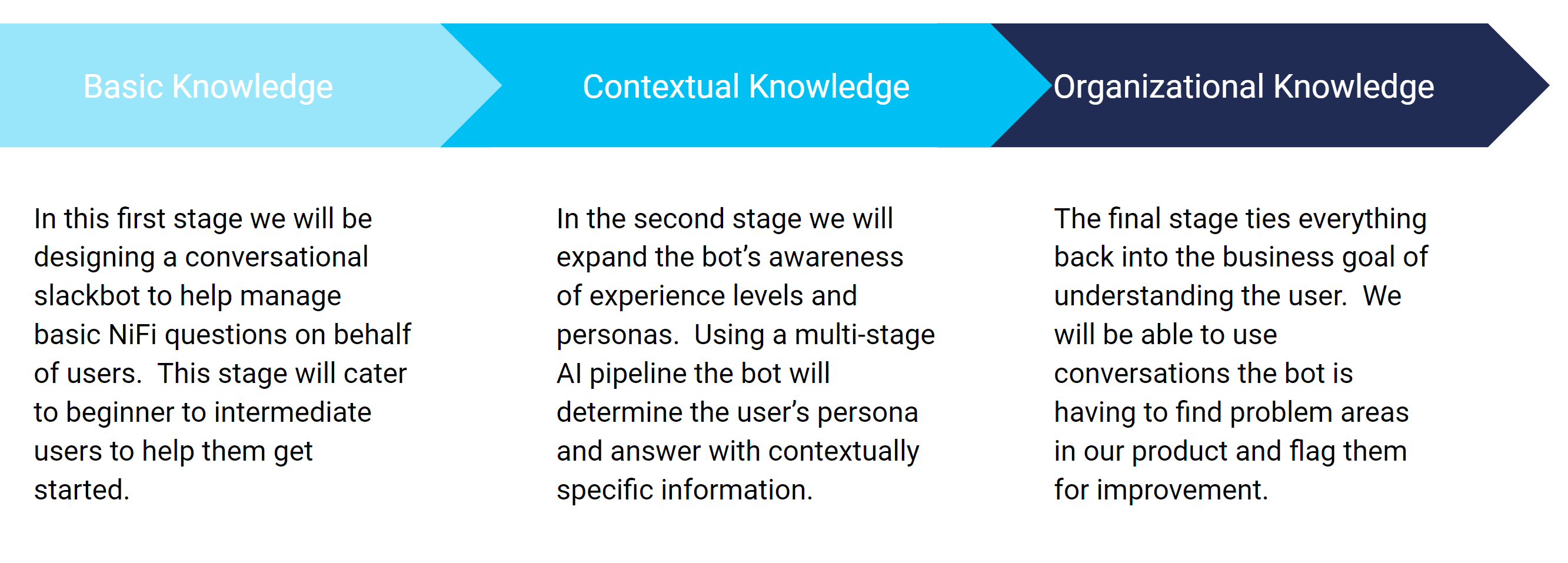
Phase 1 – “Basic Knowledge”
We built a real time slackbot to help answer NiFi questions. To build and host this solution we leveraged Apache NiFi on the Datavolo platform, Pinecone.io vectorDB, and several functions from OpenAI. If you have interested in learning more about this solution, or implimenting it for your company please reach out HERE or contact me on linkedIn!
“Basic Knowledge” – Some Realtime Usage Examples

Database Integrations – Factually correct, the explanation of JDBC with specific databases is a nice touch.

Performance Advice – This is interesting as it tells us how to benchmark but not necessarily how to improve the flow

Learning how to Query JSONs – The second answer of adding a user defined property is one of the most classic stumbling blocks of a day 1 NiFi User

CSV Extraction – The awareness of record based controller services shows a level of knowledge beyond simply processors
The Basic Knowledge Base
The vector data is one of the most sensitive parts of this system. Depending on how data is split, vectorized, chunked, stored, and retrieved performance can swing drastically. In the case of our bot we needed the bot to have a broad comprehensive understanding of how to use Apache NiFi. We attempted 3 distinct approaches before we were happy with the results.
- Attempt 1 – NiFi has built in documentation in the form of HTML documents. We simply harvested these, chunked them on new line and stored them in a pinecone index. Ultimately this approach failed because there was too much niche information and the HTML tags caused useful information to be too sparse. This lead to a lot of garbage answers.
- Attempt 2 – We retrieved the full set of NiFi ASCII documentation and chunked that on new line. This caused the chatbot to give real answers, but not useful for Data Engineers. Of the 11 ascii docs most of them are focused for developers writing integrations and custom processors, this caused the bot to focus heavily on those answers. For example we asked it “what is the best way to parse a JSON?” and we were provided an answer about how to use JSON text to communicate with the API.
- Attempt 3 – Each of the NiFi processors has a built in short description as part of the .java file. We wrote a custom script that datamined these out and formatted a text file in the style of “The XX processor has YYY capabilities”. This was chunked line by line, encoded and stored into pinecone. Additionally we selectively loaded the “Getting-Started” guide into the db as well as it provides slightly different perspectives for data engineers. This proved to be incredibly effective. As the context was limited to only the relevant processor functionality and the chunking was customized the vector retrieval was incredibly accurate.

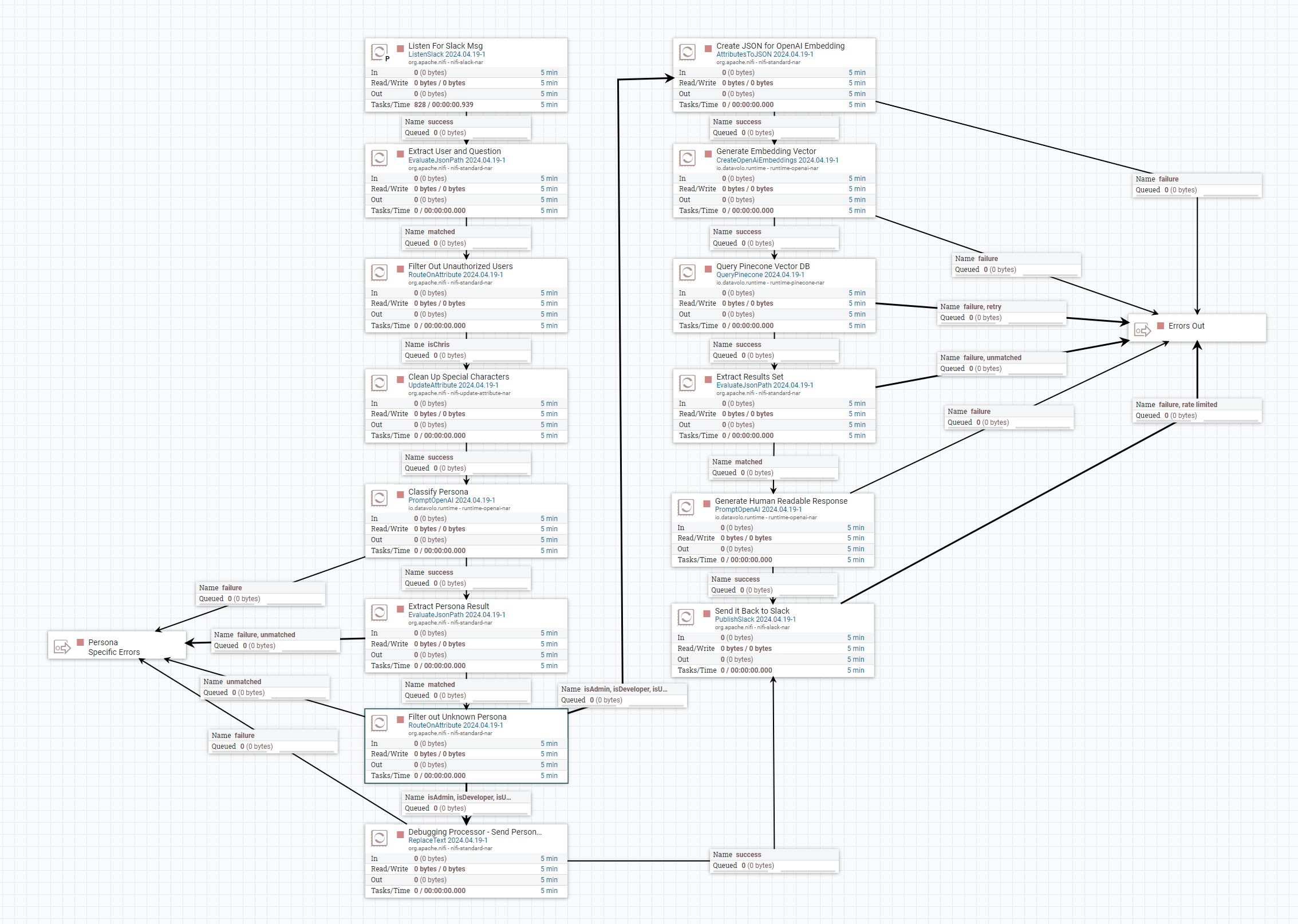
RAGs Learning Architecture
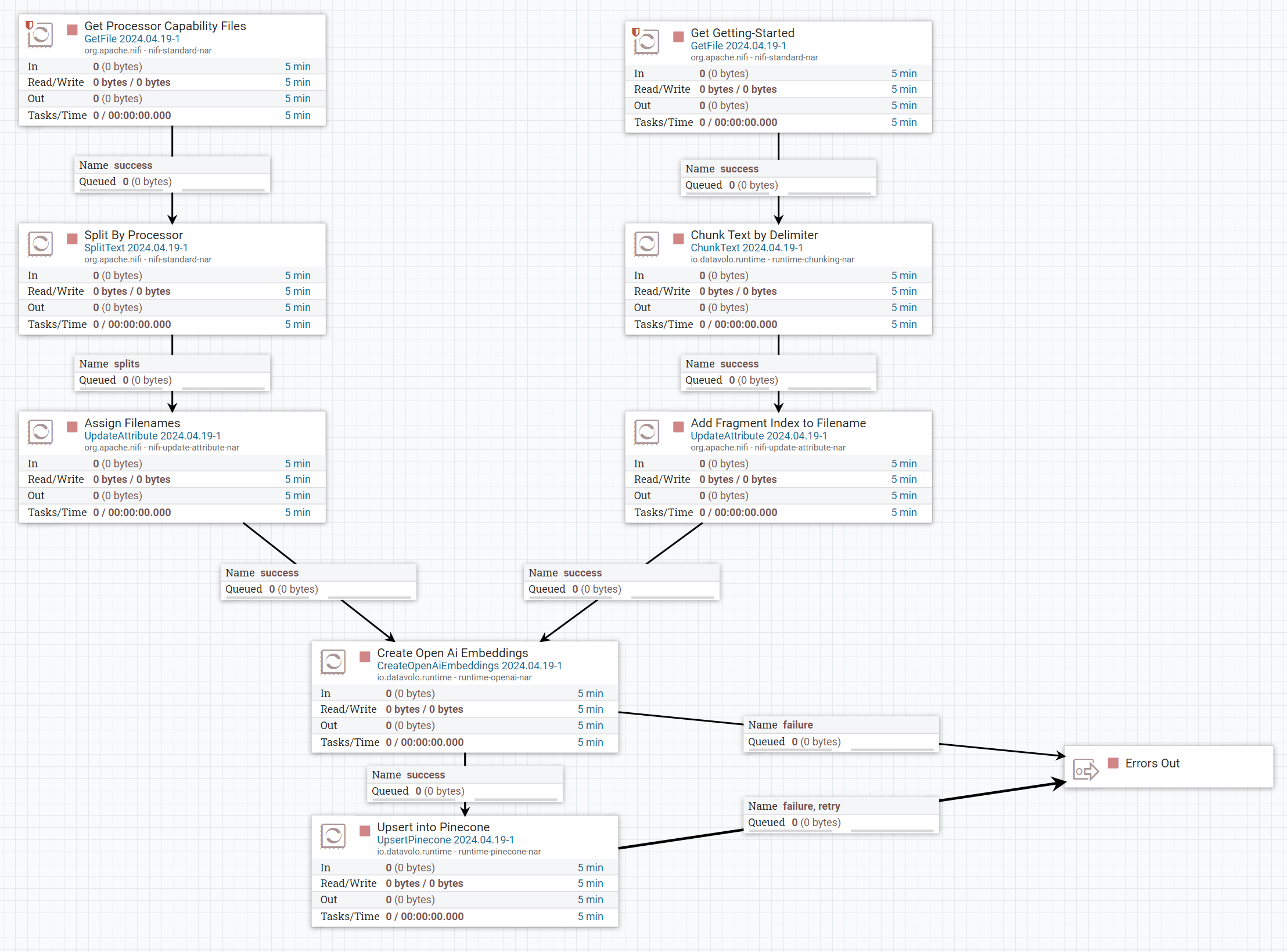
RAGs Learning Architecture – NiFi Flow
The Slackbot
The slackbot leverages existing Apache NiFi slack integration and combines it with some of the new DataVolo processors to provide a low latency question answering service. The key new processors included in this loop are:
- CreateOpenAiEmbeddings – When an incoming slack message is received it is pre-formatted before being passed to this processor. Key attributes are extracted ahead of time such as slack channel and user and only relevant message details are based to Open AI’s embedding service. This processor outputs a vector which is immediately able to be passed to the QueryPinecone processor.
- QueryPinecone – Using the Vector index we created in the previous step we are able to pass the embedded question in and retrieve the 5 most relevant matches. The fact we need to limit our results size is the primary reason Attempt 2 failed as the developer docs overwhelmed the useful results.
- PromptOpenAI – The output of QueryPinecone is reformmated to the following message and passed to OpenAI. The context is the results from QueryPinecone and the question is what was received on slackAnswer the question based on the context provided
Context : ${context}
Question: ${question}
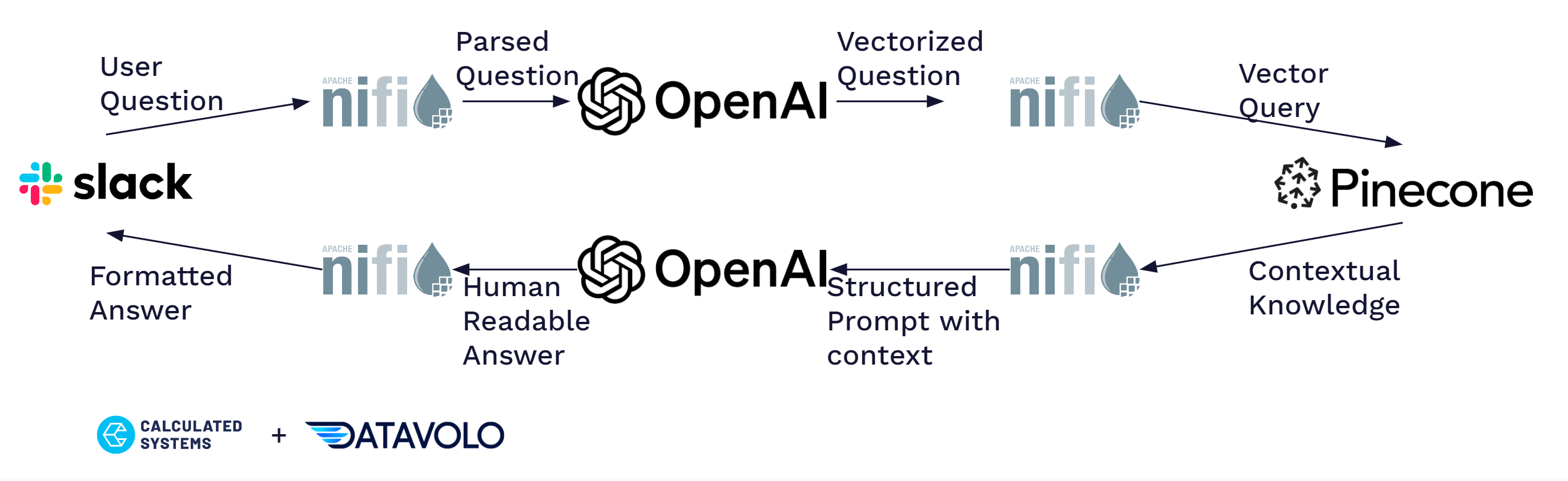
RAGs Retrieval Architecture
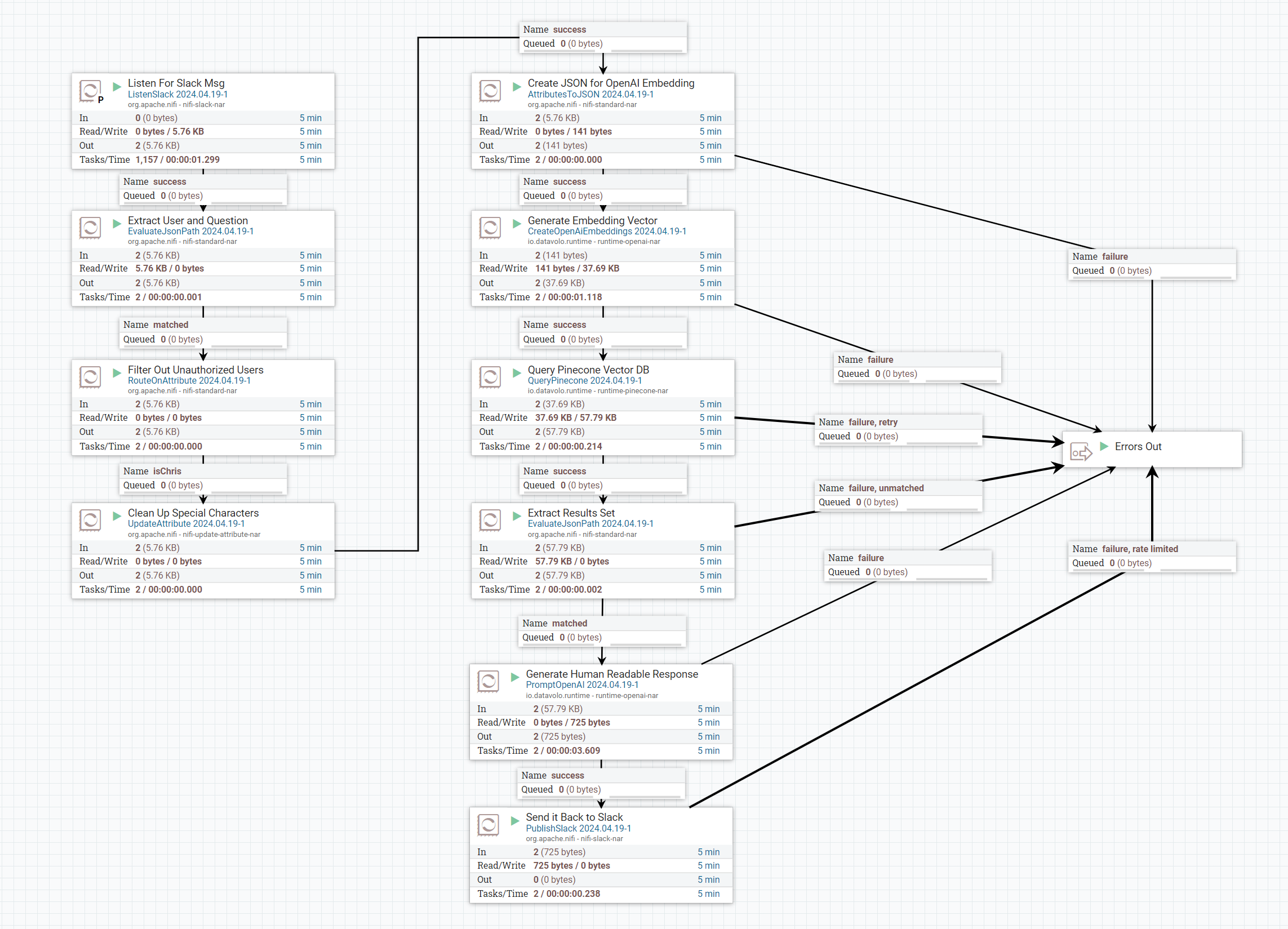
RAGs Retrieval Architecture – NiFi Flow
Phase 2 – “Contextual Knowledge”
To grow beyond the basic set of questions above we need to expand the bot’s awareness. The implementation of this requirement expands the scope of both our knowledgebase in Pinecone.io, our execution flow in NiFi and the contextual awareness of anything we send to OpenAI. To limit the scope of the project we have decided to focus on 3 distinct type of user. The “Administrator” is responsible for the provisioning and management of the NiFi cluster, this person will be mostly concerned with upkeep, stability, and system wide stability. The “User” is a classic NiFi end-user, a data engineer or data scientist looking bot build efficient pipelines. The “Developer” persona is limited to individuals looking to expand NiFi’s functionality with custom code, they will be mostly interested in java or python extensions.
“Contextual Knowledge” – Some Realtime Usage Examples
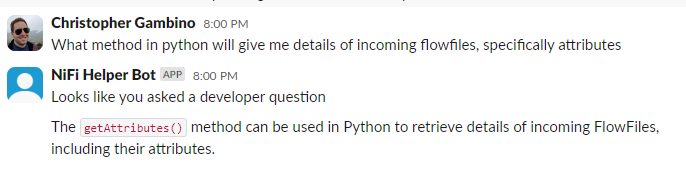
Developer Context
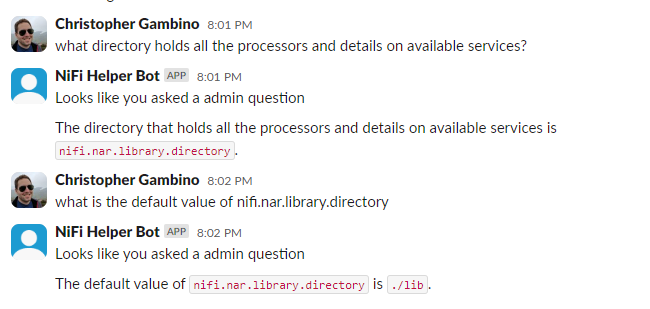
Admin Context
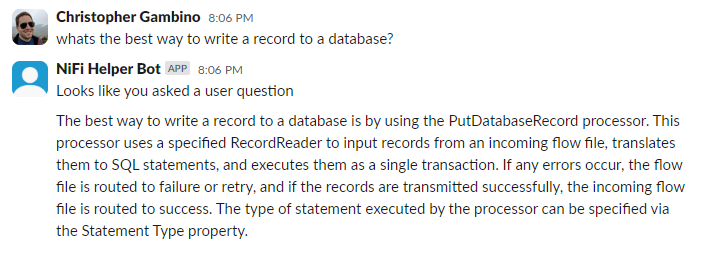
User Context
The Contextual Knowledge Base
Inorder to accommodate the increasingly varied amount of information stored in our vector database we need to upgrade our implementation. There are 3 primary ways to segregate data in Pinecone’s vectorDB.
- Indexes – This is the highest level of separation, this is primarily used to hold completely different use cases or data that were encoded with different models.
- Namespaces – While still a hard partition between data the namespaces all live in the same index. Namespaces must be queried one at a time and still represent a logical separation. This tier is useful for separating User data, or information that should not be joined.
- Metadata – Each vector uploaded to a namespace can be tagged with metadata. As these all live in the same namespace users are able to query all the vectors together or segregate on metadata. This is ultimately the right choice for our project
We upgraded our incoming document stream to assign a metadata tag to each of the documents used to create the knowledgebase. If you recall in the previous phase “attempt 2” of creating a vector DB created inaccurate answers, this approach improves on that
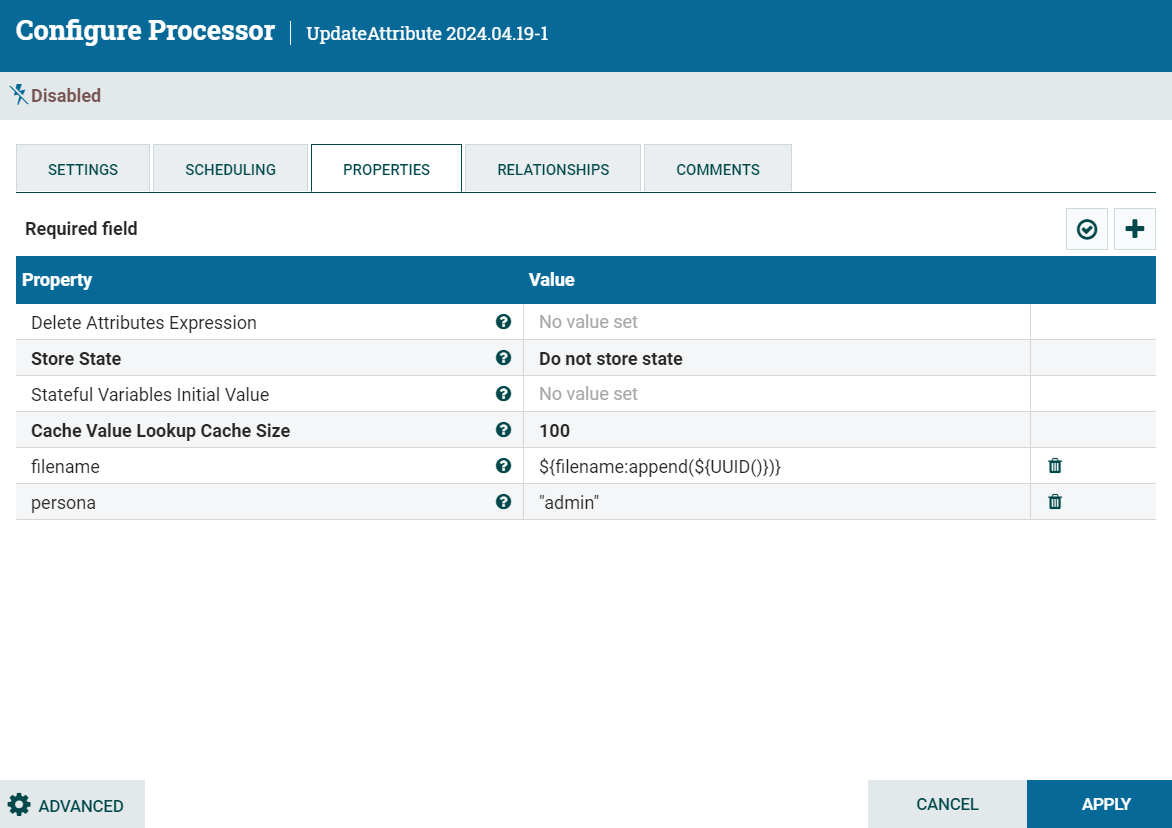
Step 1: Assigning Metadata at Ingest
Step 2: Updating record data to have a metadata field
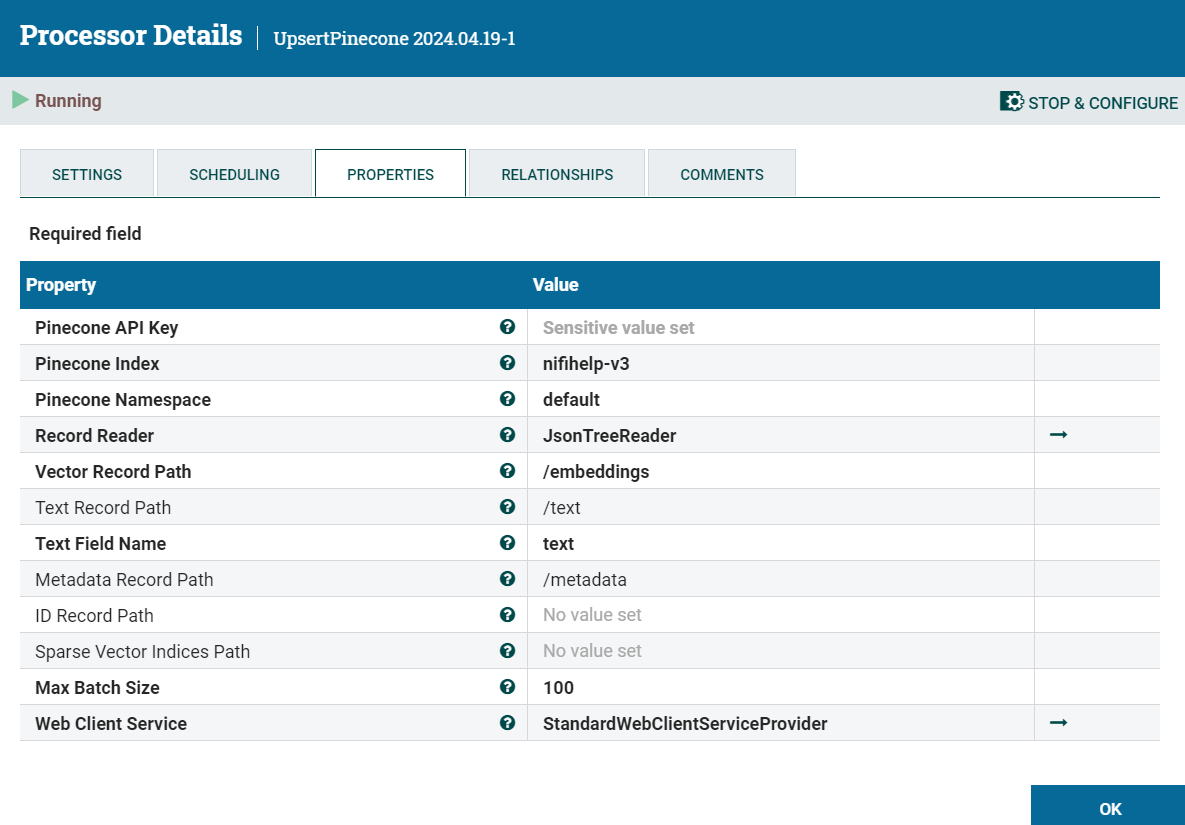
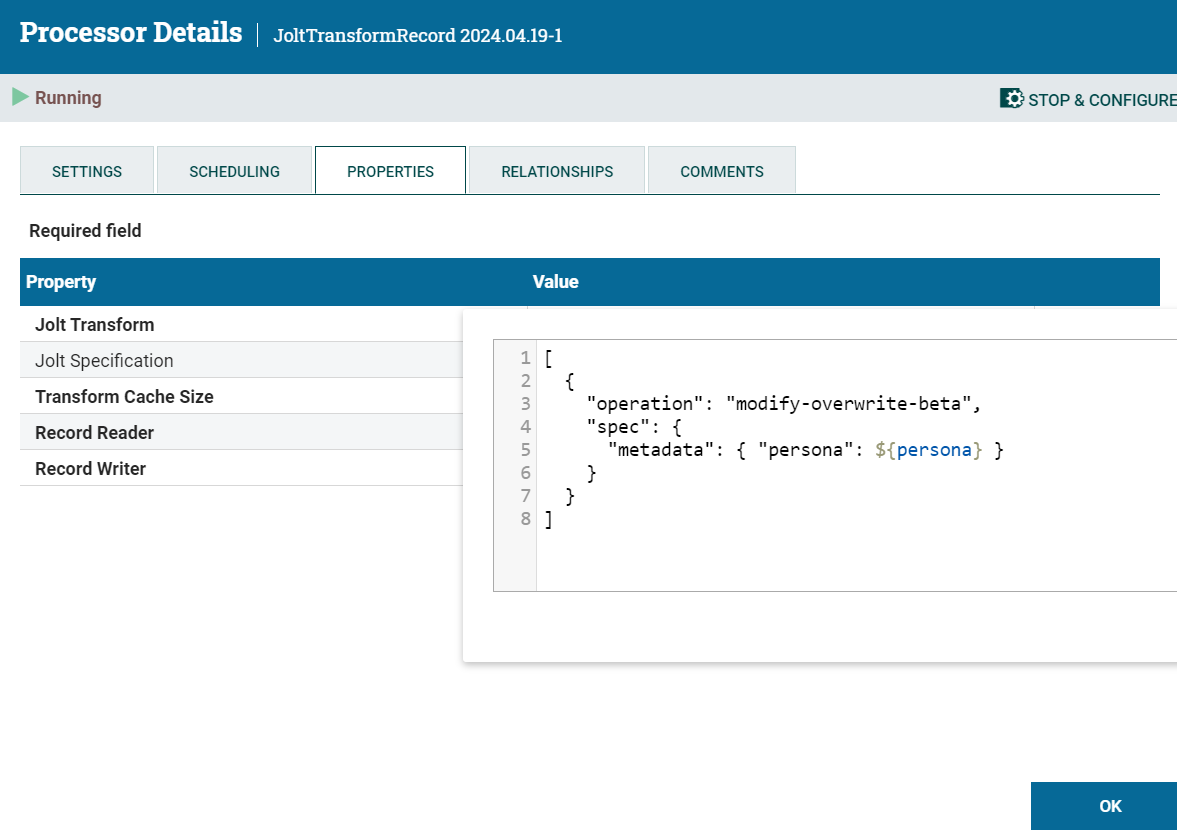
Step 3: Including metadata as part of Datavolo’s upsertPinecone processor
Classifying Personas
Inorder to gage a person’s persona we can continue to leverage OpenAI. This leads us to a two stage design in which we first ask the generative bot to classify the question, which is then carried forward to filter available metadata tags in the vectorDB. This then goes back into our existing pipeline of answering the question and sending the results back to slack.
The key here is to provide a highly structured question to OpenAI inorder to limit the answers it can provide back. This is a truncated version of the prompt used, we also limit it to a JSON response so our system can parse the result easily:
user – this persona is interested in building nifi flows, they may ask questions about controller services, nifi processors, and general data engineering. this is the most common persona
developer – this persona is customizing how nifi works and may ask questions about the Java or python integrations, the key is this user is interested in modifying nifi’s core functions with custom components. Typically this user will specify a language, or ask specifics around the creation of a custom processor or service and not existing services.
admin – this persona is incharge of administrating nifi, server administration, and managing the other users. questions may be about server settings to help nifi operate but not anything about using nifi itself. they will ask questions about operating systems, runtime environments and management.Based on these 3 personas, responding only with the word name “admin,developer,user” in the response json with the field name of persona which persona fits the question best?
Question: ${question}
Two Stage AI Pipeline
Phase 3 – “Organizational Knowledge”

The TLS toolkit is a common area for new admins to have questions

Record processing can differ from traditional JSONPath formats
Helping users on a case by case basis, although cool, doesn’t maximize the return this type of bot can provide. We can expand the bot’s functionality again to provide insights into the users asking questions of it. These insights can drive key insights like “What are the problem parts of my platform” or even more directly drive “what has this sales prospect been asking about?” We need to implement 2 main innovations to achieve these goals:
- Query memory – Incoming questions must be stored in a secure fashion that enables later statistics to be generated from them. This can be a challenge due to PII and sensitive data being included in queries. In this blog we will only be addressing some concepts how to store it, the discussion of data redaction is not included.
- Analytical Query Segregation – A separate channel and/or authorization scheme must be established in order to handle analytics queries. This query pipeline will require separate data conditioning to achieve good results.
Query Memory
Query memory can mean several things, from raw text storage on a disk, to a traditional relational database or even another Index on a vector database. Many usecases likely justify some combination of all 3, especially the relational database but for this blog we are going to stick with the vector database. This enables us to ask analytics question about specific topics and get user questions back. In the case of Pinecone we elected to store two pieces of metadata alongside the text and vector, “user” and “persona”. These two pieces allow the application to either filter by sales prospect or user type

Sample Pinecone Row
Analytical Query Segregation
This goes beyond the scope of the blog so to keep things simple, we will authorize user’s by slack username and identify analytical queries by a key leading phrase of “analytics mode :”
Query Processing
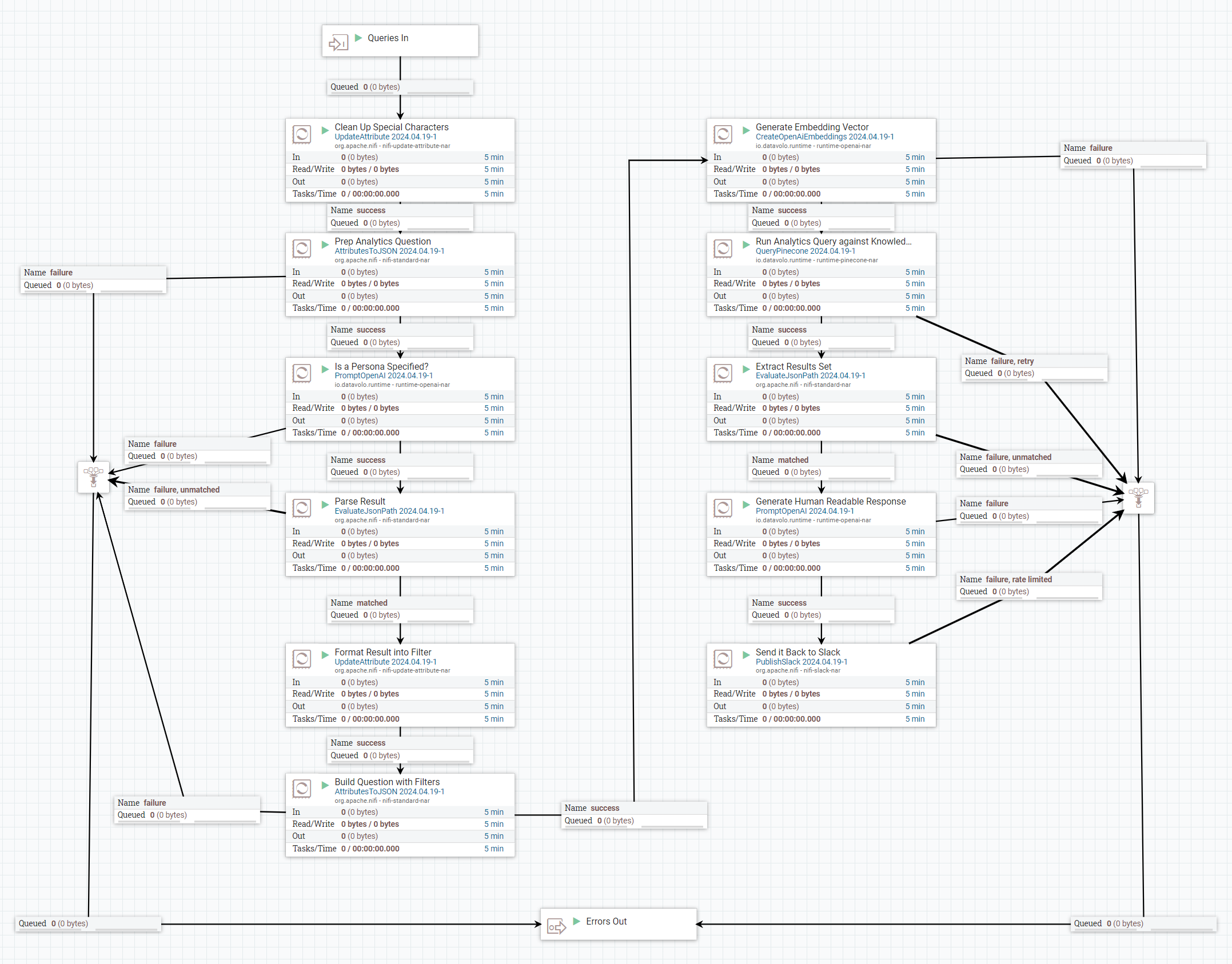
2 Stage AI – Identify query subject and interpret results
Conclusion
Generative AI, especially RAG architecture is becoming increasingly accessible to companies. The design outlined in this article can be applied to many forms of knowledge store to create a more customized and specialized set of responses. Please visit the Calculated Systems website or contact me directly if you have any questions or want to learn how to implement this at your company!