Performing OCR Analysis on an S3 Bucket in Apache NiFi
Calculated Systems has introduced new custom-made NiFi processors focused on making machine-learning accessible and easy to use. This article will guide you through setting up a process to analyze and extracting text out of images and PDFs stored in an S3 bucket.
Our OCR-capable processors from the AWS suite leverage Amazon’s Textract service, which is a set of libraries focused around OCR capabilities. OCR stands for optical character recognition, and the term is used to describe algorithms and systems that can detect characters/text from images or documents. OCR can be used in a variety of applications, including tabulating scanned documents, extracting text from signage captured in photos, and much more.
Getting Started
We will start with the more basic processor in our Textract family – the DetectDocumentText processor. Our Textract processors are directly tied to both Amazon Textract and Amazon S3. We will discuss later on how exactly data is imported into and exported out of the processor. For right now, here’s the tools and information you’ll need:
-
A certified NiFi instance
-
Access to an Amazon account with permissions to Textract and at least one S3 bucket
-
The AWS region in which both Textract and your S3 buckets reside in
All AWS-related processors (including those that we didn’t create) require credentials. You can either put in the credentials information directly into the processor, or create a credential provider service. Either method is valid, but I will be using the latter, since it allows me to input the credentials once, and reuse them in other AWS-related processors via the provider service..
If you are unsure of how to link your AWS credentials to a NiFi processor, read Chris’ article on how it works!
Creating the Flow
My flow looks like this, and I’ve explained how it works below:
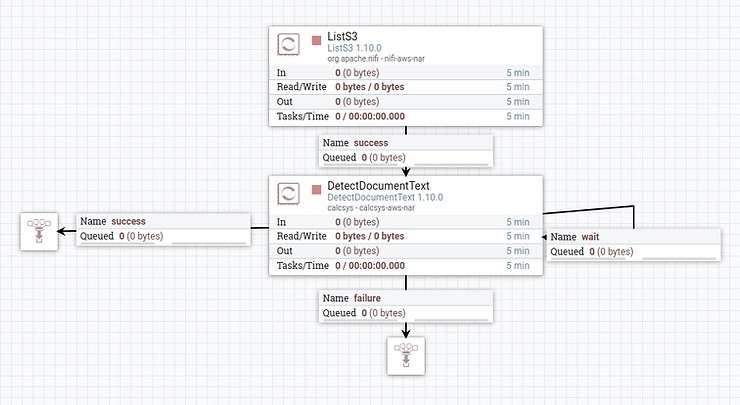
The ListS3 processor will list all of the files in the bucket of your choosing, and attach identifying information about each file, such as its name, bucket, and others as attributes to a FlowFile. This FlowFile will then flow into the DetectDocumentText processor, which will take in the metadata about the S3 object, and tell the Textract API to download and analyze it. This is why you do not need to download the files with something like the FetchS3 processor upstream.
The relationship from the processor that points into itself is called a wait relationship. This is where FlowFiles whose jobs have not completed go to wait. They will flow around and around the wait queue until their Textract job has been completed, where they will then flow out to the success line. Some will exit this queue faster than others – it depends on the document size, or if it’s a PDF, the number of pages. These “waiting” FlowFiles are not creating new jobs – they are simply checking on the progress of the job they started when they first entered the processor.
Configuring the Processors
Configuration of the Textract processors is very straightforward. The configuration straight out of the box is to grab the S3 bucket name and entity name from the incoming FlowFile, thanks to NiFi’s expression language. The only thing you need to do is attach your credentials, ensure the region is as it should be, and connect the processor up!
Now you’re ready to run the processor! While the algorithm analyzes the document, you’ll see the FlowFiles in the wait queue. Some will exit this queue faster than others – it depends on the document size, or if it’s a PDF, the amount of pages.
The output structure is documented on our official processor documentation, along with an example output for comparison.
Wrap Up
Congratulations! You can now extract and analyze text from images using Apache Nifi! If you need more control over how items are detected, or would like to parse data out of forms and tables, you can use our AnalyzeDocument processors. It behaves in accordance to AWS’ documentation, so if you are unsure of which processor to use, compare their functionality.
