101 – What Is Apache NiFi? The Core Concepts
Use our Auto-Launching NiFi Image to Follow Along [Click Here]
What is Apache NiFi? Apache NiFi is a processing engine that allows you to treat information flow as a series of events. NiFi works as an event processor and an information controller. It allows you to stop thinking in terms of batch operations, which is great for processing big data. Instead of waiting for data to be fully loaded so that it may be batch processed, you may use NiFi and process your SQL databases as individual rows. This allows you to enrich and serve data to the end consumer much faster. Plus, if there is a corrupt value, then it only affects the chunk of information that is being processed, it doesn’t affect the entire procedure in the same way it would if you were processing your data in one big chunk.
NiFi Is Made Up Of Flowfiles, Flowfile Processors And Connections
Try to think of NiFi as something that treats information flow as a series of events. File arrives/is retrieved, file is read, file is altered, file is moved somewhere else. In simple terms, it is made up of a file, a tool for reading and altering the file, and a tool for directing the file somewhere else.
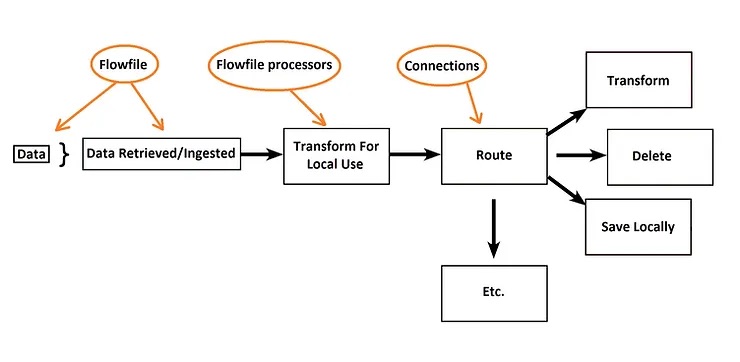
Flowfile
This represents a single piece of data within NiFi. The Flowfile is made up of two parts, there is the Flowfile Content and the Flowfile Attributes. The content is also known as the Payload, and it is the data represented by the Flowfile. The attributes are the characteristics that provide context and information about the data. The attributes are made up of key-value pairs. Each Flowfile starts out with a default set of attributes that may be added to with the use of additional operations. Here are the standard default attributes for a Flowfile.
uuid: This is a unique identifier for the Flowfile
filename: This is the name of the file that is human-readable, and is used when storing data to an external service or on a disk
path: This is a hierarchically structured value, and it is used when storing data to an external service or disk, which ensures the data is not stored in a single directory
Use our Auto-Launching NiFi Image to Follow Along [Click Here]
Flowfile processors
A Flowfile is a self-contained segment of code that usually has outputs and inputs. Flowfile processors do all the work in NiFi. For example, a common processor is the GetFTP, which will retrieve files from your FTP and will create a Flowfile. The Flowfile it creates will include attributes about which directory the data was retrieved from. These attributes include the filename, creation date, and a payload containing the file’s contents.
The Flowfile in our example may then be processed by RouteOnAttribute, which is another common processor. The processor will examine the Flowfile, and before passing the Flowfile down the chain, it will apply user-defined logic based on the Flowfile’s attributes
Connections
As you know, a connection is required to send commands and receive answers. Flowfiles have to travel between processors. “Connections” determine how they travel between processors. The most common connections are failure and success connections, which work as a method of simplified error handling for processors.
A processor such as the RouteOnAttribute processor will have its own custom connections based on whichever rules were created. A user may have a connection auto-terminate if the user immediately wishes to discard a certain type of event. For example, some users deal with duplicates by having duplicate files immediately discarded using processors and connections.
A Flow Incorporates These Three Concepts
In the image below, you can see the three basic steps that make up the NiFi system. A processor retrieves files/data from a local directory and turns it into a Flowfile. In the image below, the Flowfile goes through a connection that send puts the data into Hadoop.
Configure Processors By Clicking Tabs
When you configure a processor, you will see tabs. To get to the configuration screen right click a processor and simply click “configure.”
Here is what each of the tabs do:
The Settings Tab
Here you may auto-terminate relationships and you may rename how each processor appears. If your processor allows you to create user-defined relationships, then they will appear in this tab after they are created. The advanced settings allow for things such as yield duration and penalty, and things such as how to handle retrying Flowfiles if the first attempt is a failure.
The Scheduling Tab
There are several different scheduling options available for each processor. Many people find the timer-driven strategy the most appropriate. For example, many people set their NiFi to run as fast as NiFi can schedule it, which means NiFi will process whenever data is available, and this is achieved by setting the scheduling period to zero seconds.
Other people may prefer a specified interval schedule, so they set their scheduling period to a certain number of seconds. It is possible to increase the concurrency on this tab, which will allocate additional threads to your processor.
The Properties Tab
Amend and configure your settings in the properties tab. For example, a processor may allow the configuration of custom properties. If so, click the plus sign located at the top-right in order to add them. Some properties will allow for the NiFi Expression Language.
If you want to know if a property allows for the NiFi Expression Language, you may hover your mouse cursor over the question mark icon located next to the property name. This will show a true or false, which indicates if it supports the NiFi Expression Language.
The Comments Tab
This allows developers the ability to add comments at a per-processor level. They are used in the same way coders may add comments to lines in a program. They are for the edification of other developers, and/or to remind developers of something, they have no effect on the function of NiFi.
Continue our Self-Paced Training Series: Expression Language
https://www.calculatedsystems.com/post/the-nifi-expression-language
Learn more about Apache NiFi by downloading the free ebook Apache NiFi for Dummies: https://www.calculatedsystems.com/nifi-for-dummies
